A transcription factor activates a promoter. A repressor blocks expression of a reporter. A plasmid depends on a specific backbone. A design workflow may require one assembly step before another. A gene circuit may contain a cascade, a feedback loop, or an incoherent feed-forward motif.
Tables are still useful here, but in this chapter we will introduce another way to think about biological structure: graphs.
A graph is a collection of nodes connected by edges.
In synthetic biology, nodes might represent:
genes
proteins
promoters
guide RNAs
plasmids
strains
assembly steps
analysis stages
Edges represent relationships between those things.
Examples include:
activation
repression
binding
dependency
derivation
assembly order
information flow
Graphs help us move from “what values are in this table?” to “how is this system connected?”
In this chapter, we will learn how to represent biological relationships in Python using tidy tables and NetworkX.
9.1 Graphs as tidy data
In Chapter 5, we introduced tidy data and agreed to use it as the default tabular format from that point onward.
That convention continues here.
When we represent a network in a table, we will usually use one of two tidy tables:
a node table, where each row is one node
an edge table, where each row is one edge
This is a very practical habit.
A tidy edge table is easy to:
read from CSV
inspect with pandas
filter by interaction type
merge with metadata
save after curation
convert into a graph object when needed
Likewise, a tidy node table makes it easy to attach metadata like:
part type
sequence length
host organism
plasmid name
copy number class
fluorescent protein color
design status
So although we are introducing graph thinking, we are not abandoning tidy data.
We are adding a graph layer on top of it.
9.2 Installing NetworkX
The most widely used pure-Python graph library is networkx.
If you need to install it, the command is:
pip install networkx
We will also use pandas, which we already introduced in the previous chapter.
9.3 A first regulatory network
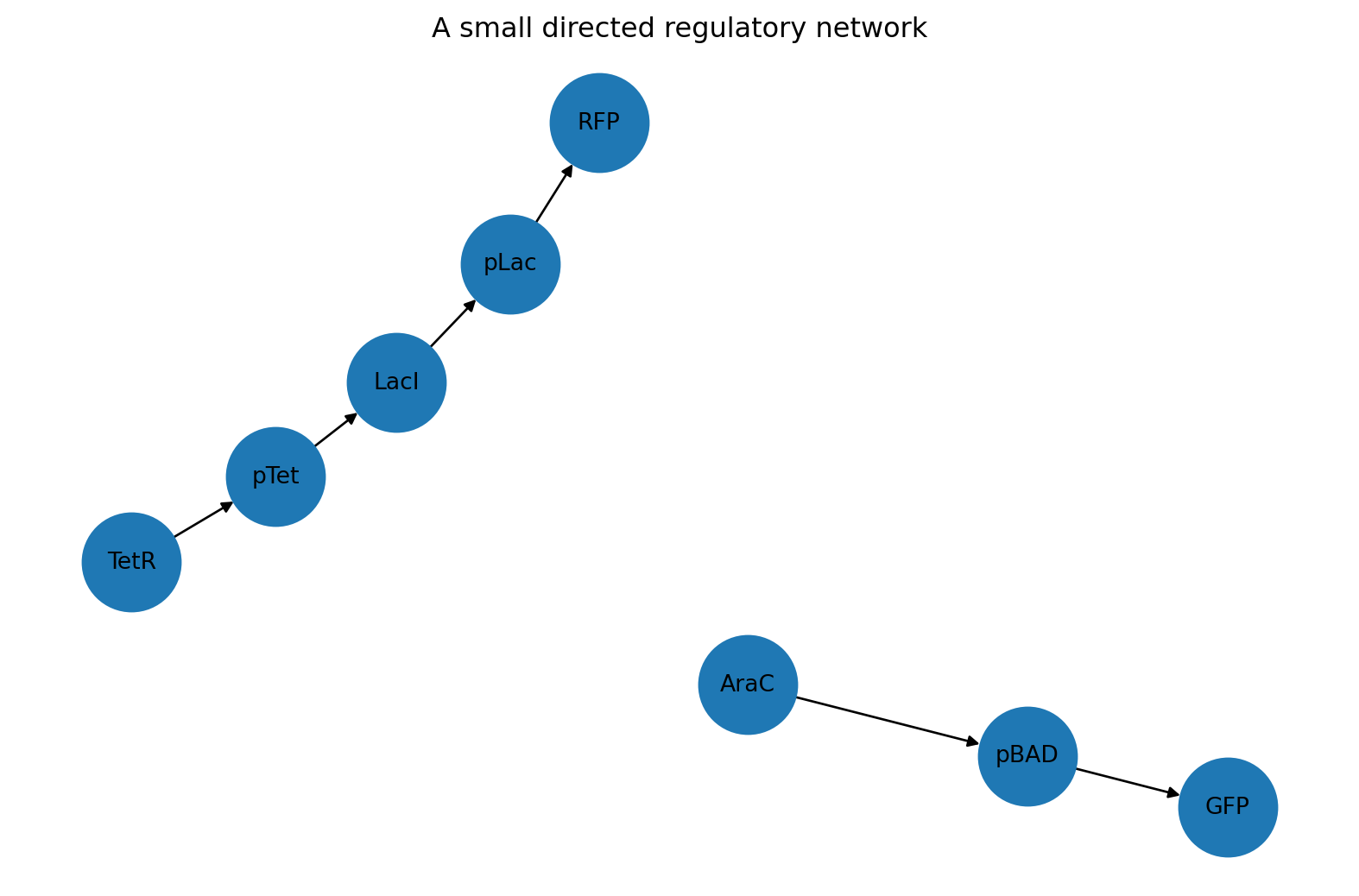
Let us begin with a simple gene regulation example.
Suppose we have a sensor circuit with these relationships:
AraC activates pBAD
pBAD drives expression of GFP
LacI represses pLac
pLac drives expression of RFP
TetR represses pTet
pTet drives expression of LacI
We can represent those relationships as a tidy edge table.
Because this graph is not acyclic, a topological sort would fail.
That kind of check can prevent subtle mistakes in automation pipelines and project planning.
9.16 Merging tidy metadata with graph results
Because we began with tidy data, we can summarize graph structure and merge it back into tables.
For example, we can compute the in-degree and out-degree of each node in our first graph.
degree_summary = pd.DataFrame( {"node": list(G.nodes()),"in_degree": [G.in_degree(node) for node in G.nodes()],"out_degree": [G.out_degree(node) for node in G.nodes()], })node_summary = node_table.merge(degree_summary, on="node", how="left")node_summary.sort_values(["kind", "node"])
node
kind
role
in_degree
out_degree
1
pBAD
promoter
input promoter
1
1
4
pLac
promoter
regulated promoter
1
1
7
pTet
promoter
regulated promoter
1
1
0
AraC
protein
regulator
0
1
2
GFP
protein
reporter
1
0
3
LacI
protein
repressor
1
1
5
RFP
protein
reporter
1
0
6
TetR
protein
repressor
0
1
This is exactly the kind of workflow that scales well:
store the network in tidy tables
convert to a graph
compute structural properties
bring those results back into tidy tables
continue analysis with pandas
That pattern will keep appearing throughout computational biology.
9.17 Choosing between a table and a graph
A good practical question is:
When should I use a table, and when should I use a graph?
Use a tidy table when you want to:
store curated interactions
edit metadata
merge with experimental measurements
save or exchange data
filter and summarize observations
Use a graph object when you want to:
follow paths
detect cycles
inspect predecessors and successors
compute connectivity measures
reason about motifs and dependencies
In practice, most good workflows use both.
9.18 Exercises
Create a tidy edge table for a repressilator-like circuit with three repressors in a cycle.
Convert that table into a directed graph and confirm that it contains a directed cycle.
Add a tidy node table with metadata such as kind, host, or copy_number_class.
Write a function that returns all direct targets of a regulator.
Write a function that counts how many activating and repressing edges exist in a graph.
Build a dependency graph for a DBTL workflow and compute a valid topological order.
Export one of your graphs back into a tidy edge table and save it as CSV.
9.19 Recap
In this chapter, we introduced graph thinking for synthetic biology.
The most important ideas are:
a graph contains nodes and edges
many biological relationships are naturally directed
tidy edge tables and node tables are the best default storage format
networkx lets us convert tidy tables into graph objects for analysis
graph objects help us inspect paths, cycles, feedback, motifs, and workflow dependencies
after graph analysis, we can move results back into tidy tables for further work
That final point matters a lot.
We are not replacing tidy data. We are extending it.
From here onward, when we deal with network structure, pathway logic, or design dependencies, we will still prefer tidy tables as the standard exchange format, and use graph objects as computational tools on top of them.